RAG vs Graphes de connaissances : guide de décision pour développeurs
Équipe Synalinks
RAG vs Graphes de connaissances : guide de décision pour développeurs
Vous construisez un agent IA et vous devez lui donner accès aux données de votre entreprise. La réponse par défaut a été le RAG : encoder vos documents, les stocker dans une base vectorielle, et récupérer les fragments pertinents au moment de la requête. Simple, rapide, bien documenté.
Mais à mesure que les équipes passent de prototypes à la production, une architecture différente revient sans cesse : les graphes de connaissances. Et les résultats sont difficiles à ignorer. Les approches basées sur des graphes de connaissances surpassent régulièrement le RAG vectoriel en précision sur les domaines structurés.
Alors de quoi avez-vous vraiment besoin ? La réponse dépend de vos données, de vos questions et de vos exigences de fiabilité.
Comment fonctionne le RAG vectoriel
Le RAG vectoriel suit un pipeline simple :
- Ingestion : Prendre vos documents (PDFs, pages web, exports de base de données) et les découper en fragments
- Encoding : Convertir chaque fragment en vecteur avec un modèle d'embedding
- Stockage : Sauvegarder les vecteurs dans une base vectorielle (Pinecone, Weaviate, Qdrant, pgvector, etc.)
- Recherche : Quand une requête arrive, l'encoder et trouver les top-k fragments les plus similaires
- Génération : Passer les fragments récupérés + la requête à un modèle de langage pour produire une réponse
Points forts :
- Rapide à mettre en place. Un prototype fonctionnel en un après-midi
- Fonctionne bien avec du texte non structuré (articles, documentation, emails)
- Scale horizontalement : plus de données signifie juste plus de vecteurs
- Large écosystème d'outils et de tutoriels
Points faibles :
- Similarité n'est pas pertinence. Le fragment le plus similaire n'est pas toujours le plus utile
- Aucune compréhension des relations entre entités
- Des fragments contradictoires sont récupérés sans résolution
- Pas de chaîne de raisonnement : vous voyez ce qui a été récupéré mais pas comment c'est interprété
- La précision se dégrade quand la base de connaissances grandit et que les fragments similaires se multiplient, menant aux hallucinations des agents IA
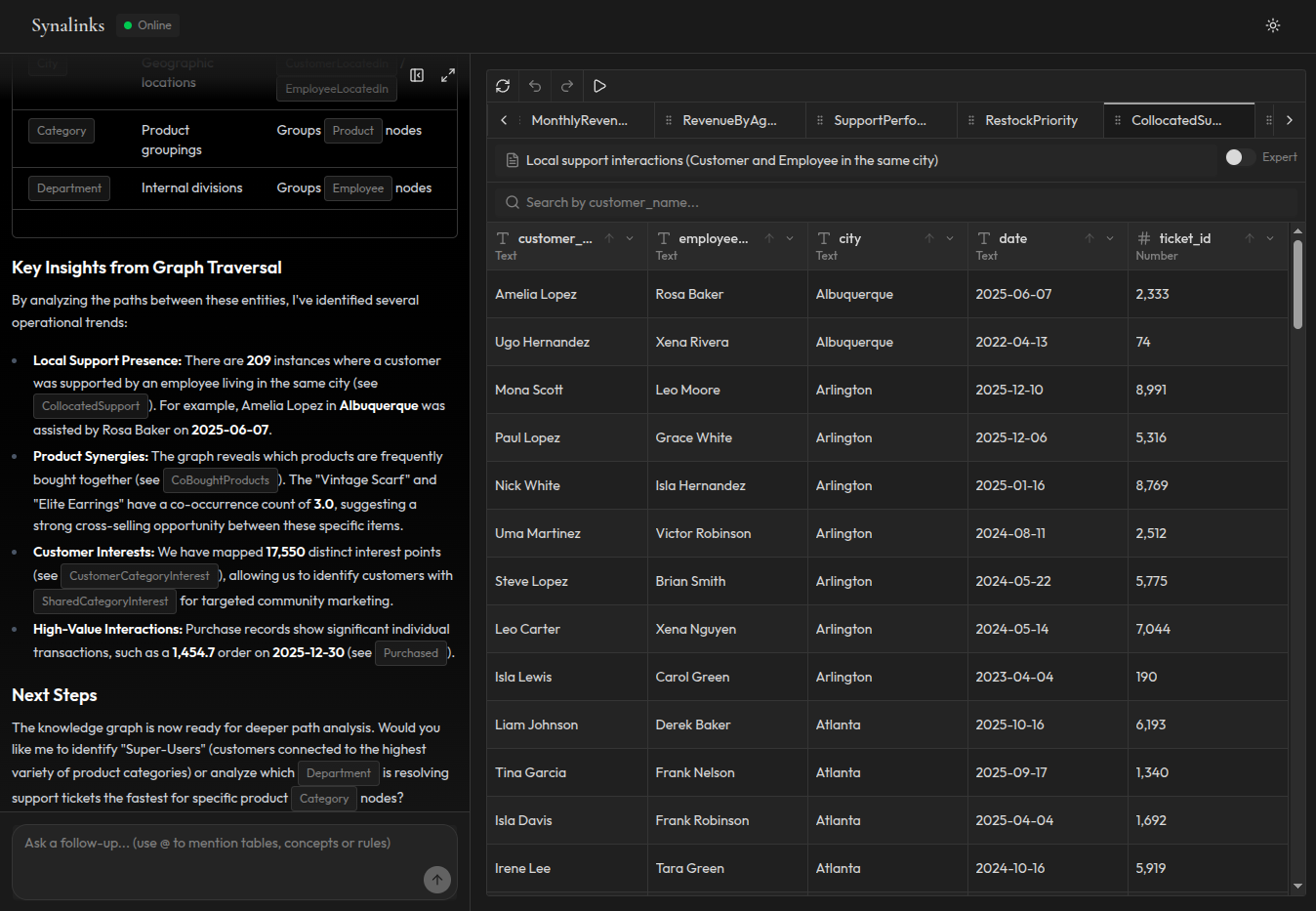
Comment fonctionnent les graphes de connaissances
Les graphes de connaissances adoptent une approche fondamentalement différente. Au lieu de stocker du texte sous forme de vecteurs, ils modélisent vos données comme des entités et des relations :
- Modélisation : Définir les types d'entités de votre domaine (clients, commandes, produits) et leurs relations
- Extraction : Peupler le graphe depuis vos sources de données, manuellement, par ETL, ou par extraction automatisée
- Vérification : Valider que les connaissances extraites sont exactes et cohérentes
- Raisonnement : Appliquer des règles et des parcours de graphe pour répondre aux questions en suivant des relations explicites
- Présentation : Formater la réponse déduite pour l'utilisateur
Points forts :
- Relations explicites entre entités : le système sait que le Client A a passé la Commande B qui contient le Produit C
- Raisonnement multi-sauts : les questions nécessitant de suivre des chaînes de relations fonctionnent naturellement
- Déterministe : la même requête sur le même graphe produit le même résultat
- Traçable : chaque réponse peut être expliquée en montrant le chemin dans le graphe
- Gère les données temporelles : vous pouvez modéliser quand les choses ont changé et raisonner dans le temps
Points faibles :
- Plus de travail initial pour modéliser le domaine et définir le schéma
- Moins flexible avec du texte purement non structuré
- Nécessite de réfléchir aux entités et relations importantes
- Écosystème plus restreint comparé au RAG vectoriel
Où les graphes de connaissances surpassent le RAG
La différence devient claire quand on regarde les types de questions auxquelles les agents en production font face :
- Requêtes structurées : « Quels clients du Plan X n'ont pas renouvelé depuis 90 jours ? » Cela nécessite de suivre des relations explicites, pas de la recherche par similarité
- Raisonnement multi-sauts : « Quel est l'impact sur le chiffre d'affaires des retards du Fournisseur Y ? » La précision du RAG vectoriel chute fortement quand les réponses nécessitent de connecter plusieurs informations. Les graphes de connaissances gèrent cela nativement
- Questions temporelles : « Montrez-moi tous les tickets liés à l'incident d'infrastructure du 15 mars. » Vous avez besoin de raisonnement dans le temps, pas de similarité textuelle
Ce sont des questions de relations et de raisonnement. Pas des questions de similarité.
Quand utiliser le RAG vectoriel
Le RAG vectoriel est le bon choix quand :
- Vos données sont principalement du texte non structuré (documentation, articles, articles de recherche) et les questions portent sur la recherche d'informations pertinentes dans ce texte
- Vous avez besoin d'un prototype fonctionnel rapidement et les exigences de précision sont modérées
- Les questions sont en un seul saut : la réponse existe dans un seul fragment et ne nécessite pas de connecter plusieurs informations
- Le cas d'usage est exploratoire : les utilisateurs cherchent des informations, pas des réponses précises et vérifiables
- Vos données n'ont pas de structure relationnelle forte : il n'y a pas de relations entité-à-entité significatives à modéliser
Bons cas d'usage : recherche documentaire, assistant de recherche, chatbot FAQ, recommandation de contenu.
Quand utiliser un graphe de connaissances
Un graphe de connaissances est le bon choix quand :
- La précision compte plus que la rapidité de prototypage. Les mauvaises réponses ont des conséquences réelles
- Les questions impliquent des relations. « Quels X sont connectés à Y via Z ? » ne peut pas être résolu par une recherche de similarité
- Vous avez besoin de réponses déterministes et reproductibles. La même question doit produire la même réponse à chaque fois
- L'auditabilité est requise. Vous devez montrer aux stakeholders (ou aux régulateurs) exactement comment l'agent est arrivé à sa conclusion
- Vos données ont une structure relationnelle : clients, commandes, produits, employés, politiques, et les connexions entre eux
- Le raisonnement temporel compte : vous devez savoir non seulement ce qui est vrai maintenant, mais ce qui était vrai à un moment donné
Bons cas d'usage : agents customer success, systèmes de conformité, agents d'analytics, aide à la décision opérationnelle, tout ce où « probablement juste » ne suffit pas. Consultez aussi notre guide sur l'architecture mémoire des agents IA pour comprendre comment les graphes de connaissances s'intègrent dans la stack mémoire.
L'approche hybride : GraphRAG
Un terrain intermédiaire émerge : le GraphRAG. Cette approche utilise un graphe de connaissances comme source principale de vérité pour les données structurées, tout en conservant le RAG vectoriel pour le contenu non structuré qui ne rentre pas dans un graphe.
L'idée est simple : utiliser le bon outil pour chaque type de données. Les relations structurées vont dans le graphe. Les documents libres sont encodés en vecteurs. L'agent interroge les deux et les résultats sont combinés.
Cela fonctionne, mais ajoute de la complexité architecturale. Vous avez maintenant deux systèmes de recherche à maintenir, deux ensembles de pipelines de données, et le défi de réconcilier des réponses provenant de sources différentes.
Ce que Synalinks Memory propose
Synalinks Memory adopte l'approche graphe de connaissances et supprime ce qui la rend difficile.
Vous n'avez pas besoin de concevoir manuellement un schéma. Connectez vos sources de données et Synalinks extrait automatiquement les entités, relations et règles. Vous décrivez votre domaine en termes naturels (« ce sont des clients, ce sont des commandes, en retard signifie plus de 30 jours après l'échéance ») et le système structure les connaissances en conséquence.
Vous n'avez pas à choisir entre structuré et non structuré. Synalinks traite les deux, structurant ce qu'il peut et préservant ce qu'il ne peut pas.
Et vous obtenez les avantages clés d'un graphe de connaissances sans la charge habituelle :
- Réponses déterministes avec chaînes de raisonnement complètes
- Extraction automatique des connaissances depuis vos sources de données
- Raisonnement temporel intégré
- Une API simple que vos agents peuvent appeler
Si vous atteignez le plafond de précision du RAG vectoriel et envisagez un graphe de connaissances, Synalinks Memory est le chemin le plus rapide de « nous avons besoin de connaissances structurées » à « c'est en production ».
Les captures d'écran sont fournies à titre illustratif. Le produit final peut différer sur certains aspects. Les données présentées sont synthétiques et utilisées uniquement à des fins de démonstration.