Graphes de contexte : les trois structures de graphes derrière des agents IA fiables
Équipe Synalinks
Graphes de contexte : les trois structures de graphes derrière des agents IA fiables
Quand un agent IA répond à une question, que se passe-t-il réellement en coulisses ? Dans la plupart des systèmes, la réponse est : un modèle de langage lit du texte récupéré et devine. Il n'y a pas de structure. Pas de trace. Aucun moyen de vérifier le raisonnement.
Synalinks adopte une approche différente. Au lieu de s'appuyer sur la génération probabiliste, le système utilise trois structures de graphes distinctes qui fonctionnent ensemble pour produire des réponses structurées, traçables et reproductibles. Nous appelons cette combinaison un graphe de contexte.
Chaque graphe gère un rôle différent :
- Les graphes acycliques dirigés (DAG) encodent les règles logiques qui extraient, structurent et raisonnent sur vos données
- Les graphes de connaissances sont la sortie de ces règles : les faits structurés et les relations que le DAG a dérivés
- Les graphes de dépendances tracent la provenance de chaque réponse jusqu'à ses sources
Comprendre comment ces trois couches interagissent est essentiel pour comprendre pourquoi le raisonnement déterministe fonctionne, et pourquoi il produit des résultats fondamentalement différents du RAG.
Graphes acycliques dirigés : le moteur qui construit la connaissance
Tout commence par le DAG. Dans Synalinks, un DAG est un graphe de règles logiques où chaque règle dépend d'autres règles ou de données brutes, sans dépendances circulaires. La partie « dirigé » signifie que les règles s'écoulent dans une seule direction, des entrées vers les conclusions. La partie « acyclique » signifie qu'aucune règle ne peut dépendre d'elle-même, directement ou indirectement. Cela garantit que l'évaluation se termine toujours et produit un résultat défini.
Le DAG contient deux catégories de logique. Les concepts extraient et reformatent les données sans effectuer de calcul : ils structurent les données brutes en entités et relations typées. Les règles effectuent de l'analytique et du raisonnement sur ces concepts pour dériver de nouvelles connaissances. Dans les deux cas, les briques de base sont les définitions Node (entités) et Edge (relations). Tous vivent dans le même DAG, évalués dans l'ordre des dépendances.
C'est ce qui rend Synalinks fondamentalement différent des systèmes qui traitent l'extraction et le raisonnement comme des étapes séparées. Le même moteur de règles qui transforme votre table de rendez-vous brute en relations patient-médecin structurées détermine aussi quels patients sont les plus fréquents. Ce sont des règles de bout en bout.
Un exemple pratique
Supposons que vous construisiez un agent IA pour analyser un système de santé. Vous connectez votre base de données à Synalinks Memory et définissez des concepts et des règles dans le même DAG :
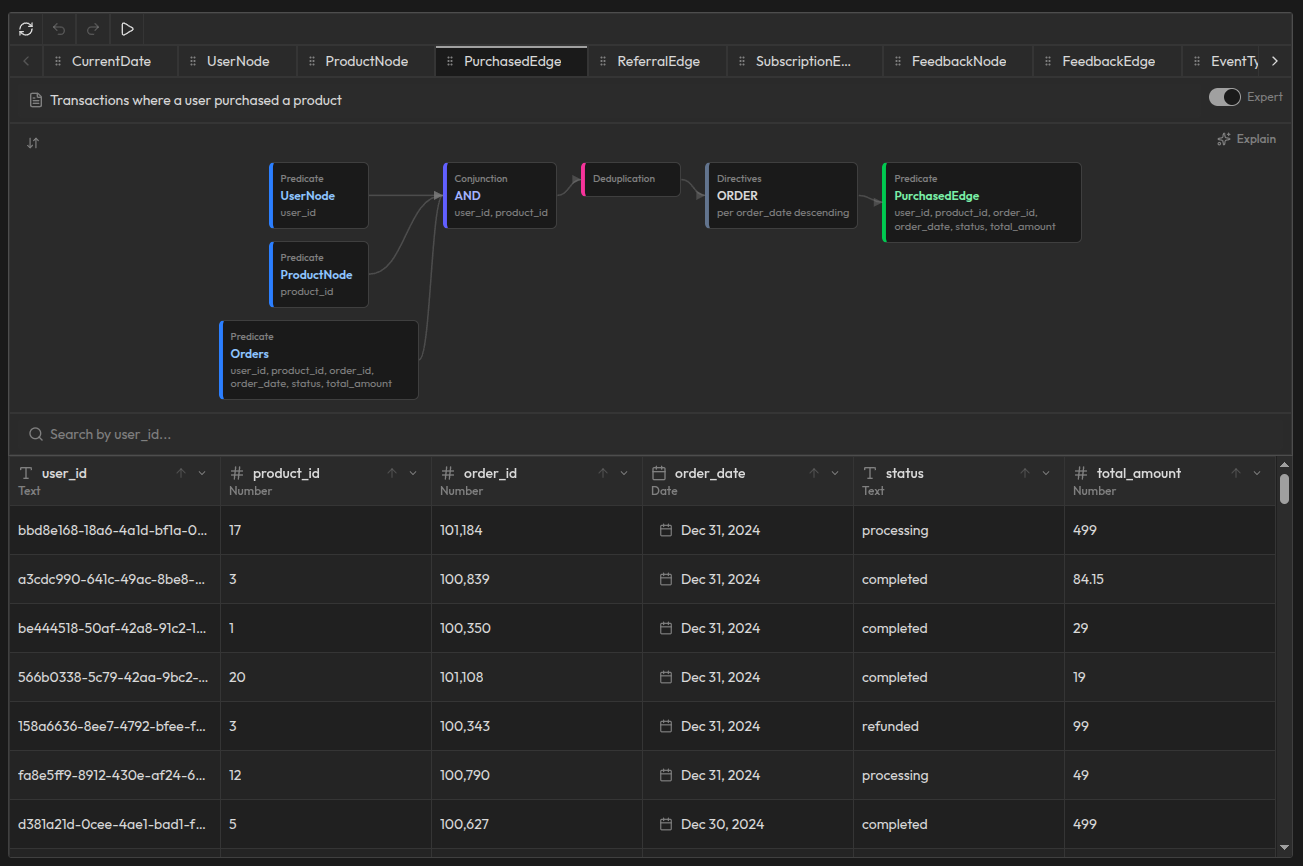
Les concepts extraient et reformatent vos données brutes sans aucun calcul. Un concept PatientNode transforme les lignes de votre table patients en entités Patient avec des propriétés typées comme l'identifiant, le nom et la date de naissance. Un concept DoctorNode fait de même pour les médecins. Un concept TreatmentNode structure les données de traitements médicaux. Côté relations, un concept HasAppointmentEdge relie les patients à leurs médecins en joignant PatientNode, DoctorNode et la table brute Appointments, appliquant conjonction, déduplication et tri pour produire des relations de rendez-vous propres et structurées. Un concept PrescriptionEdge connecte les traitements aux patients. Un concept DepartmentEdge trace quels médecins appartiennent à quels départements.
Les règles effectuent de l'analytique et du raisonnement sur ces concepts. Une règle analyse les patterns de rendez-vous pour identifier les patients les plus fréquents du système. Une autre calcule la charge de rendez-vous par département pour comprendre la distribution des ressources. Une dernière règle combine la fréquence des rendez-vous, l'historique des prescriptions et les affectations de médecins pour faire ressortir des informations sur la charge de travail des médecins, avec le nombre de patients et des métriques spécifiques.
Tous ces éléments, concepts et règles, nœuds et arêtes, forment un seul DAG. Les tables brutes de la base alimentent les concepts qui produisent des entités et des relations structurées, lesquels alimentent les règles qui produisent des conclusions dérivées comme l'analyse des patients fréquents et les métriques de charge de travail des médecins. Extraction et raisonnement dans un pipeline unifié. Pas d'étape ETL séparée. Pas de transformations de données câblées à la main. Le DAG définit l'intégralité du flux, des données brutes aux conclusions dérivées.
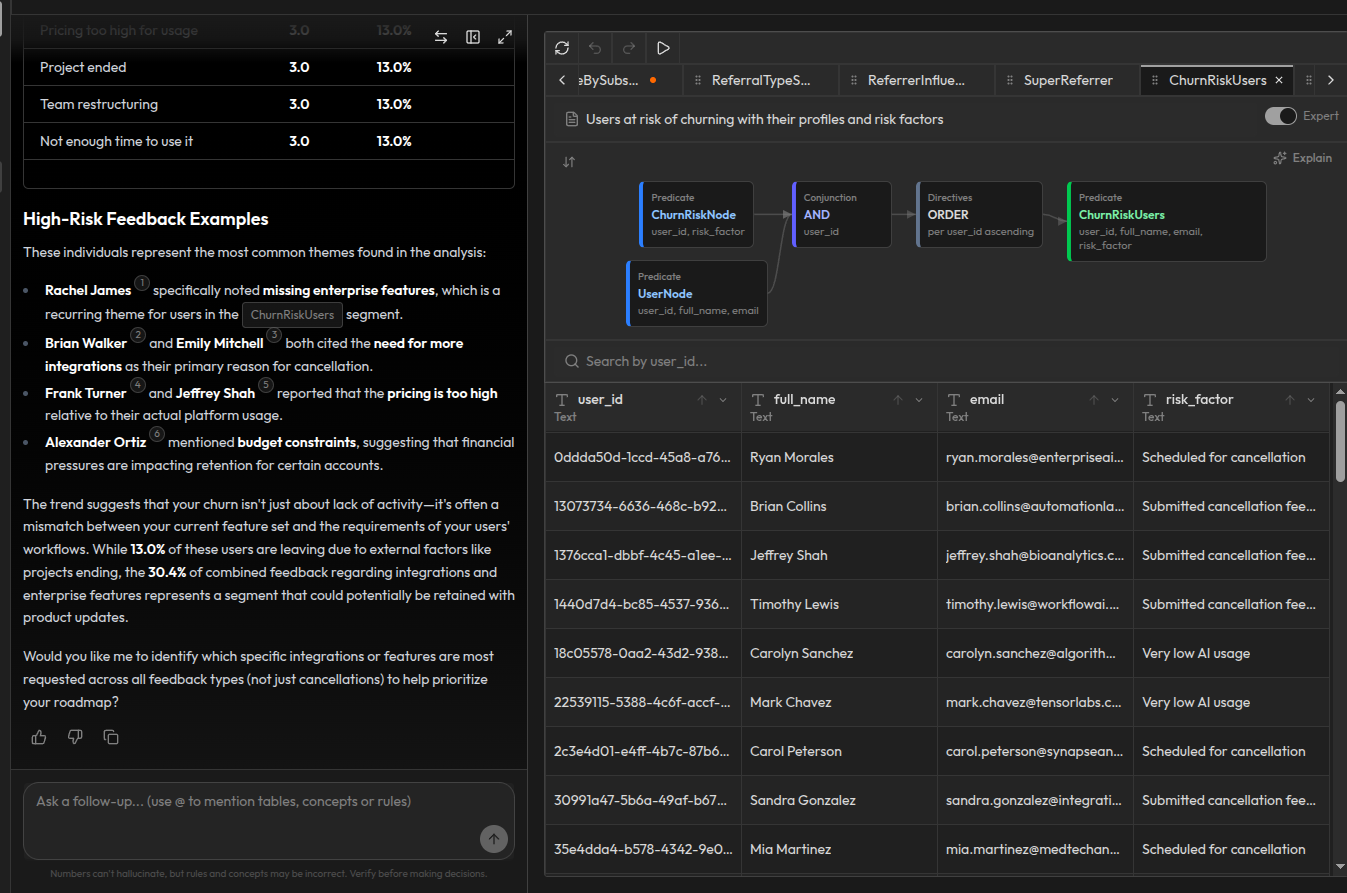
Graphes de connaissances : la sortie des règles
Le graphe de connaissances n'est pas quelque chose que vous construisez séparément. C'est ce que le DAG produit. Les concepts génèrent les entités structurées (nœuds) et les relations (arêtes). Les règles dérivent des conclusions de plus haut niveau à partir de ceux-ci. Ce résultat accumulé est le graphe de connaissances.
Prenons le concept HasTreatmentEdge comme exemple. Il prend deux entrées (PatientNode et TreatmentNode), les joint sur l'identifiant patient et l'identifiant traitement, déduplique les résultats et les trie par date. La sortie est une relation propre et structurée : quel patient a reçu quel traitement, quand et avec quels détails. Chaque ligne du résultat est une arête typée et vérifiée dans le graphe de connaissances.
Le même schéma s'applique à chaque concept. DoctorNode structure les données brutes des médecins en entités typées. HasAppointmentEdge connecte les patients aux médecins via des relations de rendez-vous. PrescriptionEdge suit les prescriptions dans le temps. Chaque concept produit des nœuds ou des arêtes qui s'accumulent dans le graphe de connaissances.
À partir des règles, le DAG dérive des conclusions de plus haut niveau : ce patient a une fréquence de rendez-vous inhabituellement élevée. La charge de travail de ce médecin dépasse les moyennes du département. Ces départements ont besoin de plus de ressources en raison de la combinaison de patterns de rendez-vous, de volumes de prescriptions et de distribution des patients.
Tous ces éléments, nœuds et arêtes produits par les concepts plus les faits dérivés par les règles, forment le graphe de connaissances. Les entités comme les patients, les médecins et les traitements ont des propriétés typées. Les relations comme « le patient a reçu le traitement » sont des arêtes explicites avec des dates et des détails, pas des inférences d'un modèle de langage. Les faits dérivés comme « le patient est un visiteur fréquent » côtoient les faits de base, tous interrogeables de la même manière.
C'est différent des approches traditionnelles de graphes de connaissances où vous modélisez manuellement une ontologie puis la peuplez. Dans Synalinks, les concepts et les règles du DAG sont l'ontologie. Ils définissent quelles entités existent, quelles propriétés elles ont, et quelles connaissances dérivées sont pertinentes. Le graphe de connaissances est une sortie vivante qui se met à jour chaque fois que les données ou les règles sous-jacentes changent.
Pourquoi c'est important
Dans un système RAG, « le patient X a reçu le traitement Y » n'est qu'un fragment de phrase flottant dans un espace vectoriel. Dans un graphe de connaissances produit par des concepts de DAG, c'est une arête typée et structurée : un patient spécifique, un traitement spécifique, avec une date et des détails, avec une dérivation claire depuis une ligne spécifique de votre table Treatments. Vous pouvez l'interroger, raisonner dessus et tracer son origine.
Graphes de dépendances : la couche de provenance
C'est là que la plupart des systèmes IA s'effondrent. Même si vous obtenez la bonne réponse, vous ne pouvez pas expliquer pourquoi elle est correcte. Vous ne pouvez pas tracer le raisonnement. Vous ne pouvez pas l'auditer. Et quand la réponse est fausse, vous ne pouvez pas identifier ce qui a mal tourné.
Un graphe de dépendances résout ce problème en traçant les connexions depuis les tables sources jusqu'aux concepts puis aux règles. Il enregistre quelles tables ont fourni les données brutes, quels concepts ont structuré ces données, et quelles règles ont raisonné dessus pour produire une conclusion.
Point essentiel : les concepts et les règles sont réutilisables. Le même concept PatientNode qui alimente une règle de patients fréquents aujourd'hui peut alimenter une analyse des résultats de traitement demain. Le graphe de dépendances trace ces connexions dans le temps, pour que vous sachiez toujours quelles sources alimentent quels concepts, et quels concepts alimentent quelles règles. Quand une table source change, vous pouvez tracer en avant à travers le graphe pour voir chaque concept et chaque règle impactés.
Et parce que le raisonnement est déterministe, les mêmes entrées produisent toujours les mêmes sorties, le graphe de dépendances n'est pas un simple journal. C'est une véritable piste d'audit. Vous pouvez rejouer n'importe quelle chaîne de dérivation et vérifier que la réponse a été correctement dérivée des sources. Cela rend l'ensemble du système véritablement auditable, de la source à la réponse.
Un exemple pratique
Vous demandez : « Quels patients ont la fréquence de rendez-vous la plus élevée ? »
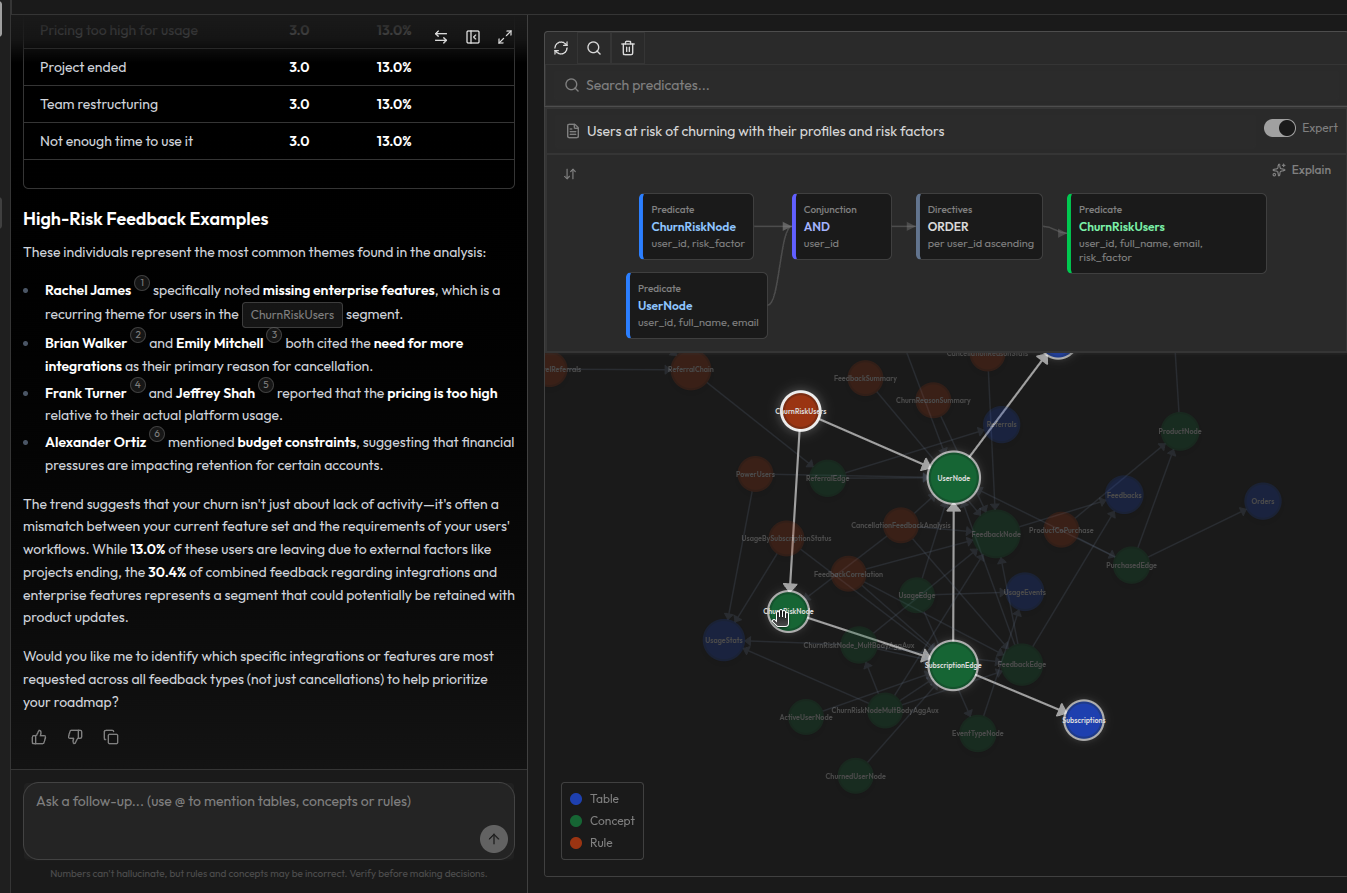
Synalinks retourne une liste de patients fréquents avec leurs profils et métriques spécifiques, accompagnée du graphe de dépendances complet expliquant comment chaque patient a été identifié. Le graphe visualise la chaîne de raisonnement complète de la source à la réponse : chaque nœud représente une table source, un concept ou une règle, et le chemin mis en évidence trace exactement comment la conclusion de patient fréquent a été dérivée.
Vous pouvez suivre la chaîne : la table patients brute alimente PatientNode, qui alimente HasAppointmentEdge, qui se connecte au médecin. La table Appointments alimente HasAppointmentEdge via PatientNode et DoctorNode. Les données de traitement transitent par HasTreatmentEdge. Tout converge vers la règle de patients fréquents, qui produit l'évaluation finale.
Chaque niveau du graphe est une brique réutilisable. Le concept PatientNode n'existe pas uniquement pour cette requête. Il est utilisé partout où les données de patients sont nécessaires. Le graphe de dépendances enregistre toutes ces connexions, pour que vous puissiez voir non seulement comment cette réponse a été dérivée, mais aussi comment la modification d'une table source ou d'un concept se propagerait à travers chaque règle qui en dépend.
Parce que le raisonnement est déterministe, cette piste d'audit est entièrement reproductible. Mêmes tables, mêmes concepts, mêmes règles, même réponse. Si la réponse change demain, c'est parce que les données source ont changé, et le graphe de dépendances vous montre exactement quelle table, quel concept et quelle règle ont été impactés. Ce n'est pas une vague attribution « ces documents ont été récupérés ». C'est une chaîne de dérivation vérifiable et rejouable, de la source à la réponse.
Comment les trois graphes fonctionnent ensemble
Les trois structures de graphes ne sont pas des systèmes séparés. Ce sont des couches du même processus :
- Le DAG définit la logique : les concepts qui extraient et structurent les données en nœuds et arêtes, et les règles qui effectuent de l'analytique et du raisonnement dessus
- Le graphe de connaissances est la sortie : l'ensemble des faits structurés et des conclusions dérivées produits par l'évaluation du DAG
- Le graphe de dépendances est la piste d'audit : traçant les connexions des tables sources aux concepts réutilisables puis aux règles, rendant l'ensemble de la chaîne reproductible et vérifiable
Quand votre agent IA interroge Synalinks Memory, voici ce qui se passe :
- Le DAG s'évalue : les concepts extraient et structurent les données en nœuds et arêtes, les règles dérivent des conclusions analytiques
- Le graphe de connaissances se matérialise : tous les faits structurés et dérivés deviennent disponibles
- Le graphe de dépendances capture la provenance : chaque étape de l'évaluation est enregistrée
Le rôle du modèle de langage se réduit à la présentation. Il reçoit une réponse structurée et dérivée avec une provenance complète, et la met en forme pour l'utilisateur. Il ne raisonne pas. Il n'interprète pas. Il communique.
Pourquoi c'est important pour l'IA en production
Si vous faites tourner des agents IA en production, vous avez probablement rencontré ces problèmes :
« L'agent a donné des réponses différentes à la même question. » Sans raisonnement structuré, il n'y a aucune garantie de cohérence. Avec un DAG de règles produisant un graphe de connaissances, les mêmes données produisent toujours les mêmes faits dérivés.
« On ne peut pas expliquer pourquoi l'agent a dit ça. » Sans suivi de provenance, les réponses sont opaques. Avec un graphe de dépendances, chaque réponse vient avec une chaîne de dérivation complète, de la conclusion jusqu'aux données source brutes.
« Une source de données a changé et on ne sait pas ce qui est impacté. » Sans suivi des dépendances, l'analyse d'impact est une devinette. Avec un graphe de dépendances, vous pouvez tracer en avant depuis n'importe quel changement de données brutes à travers le DAG pour voir chaque fait dérivé qui est impacté.
« L'agent a halluciné une relation qui n'existe pas. » Sans connaissances structurées, le modèle invente des connexions entre des fragments de texte récupérés. Avec un graphe de connaissances construit par des règles explicites, les relations comme « le patient a reçu le traitement » n'existent que si une règle les a dérivées à partir de données réelles.
Les graphes de contexte résolvent tous ces problèmes en rendant l'ensemble du processus, des données brutes aux connaissances structurées en passant par les conclusions dérivées, structurel, déterministe et transparent.
Pour commencer
Synalinks Memory implémente les graphes de contexte comme une solution clé en main pour les agents IA. Connectez vos sources de données, définissez vos concepts et vos règles, et obtenez des réponses structurées et traçables avec une provenance complète.
Pas d'embeddings. Pas de recherche vectorielle. Pas de raisonnement boîte noire. Juste des règles, des graphes et des réponses vérifiables.
Les captures d'écran sont fournies à titre illustratif. Le produit final peut différer sur certains aspects. Les données présentées sont synthétiques et utilisées uniquement à des fins de démonstration.