GraphRAG vs Synalinks : la recherche n'est pas du raisonnement
Equipe Synalinks
GraphRAG vs Synalinks : la recherche n'est pas du raisonnement
GraphRAG est devenu la reponse par defaut quand les equipes realisent que le RAG vectoriel classique ne suffit plus. L'idee est simple : utiliser un modele de langage pour extraire des entites et des relations depuis vos documents, construire un graphe, puis interroger ce graphe au lieu d'un simple vector store (ou en complement).
C'est un vrai progres. Mais il porte encore deux limitations fondamentales que la plupart des equipes ne remarquent qu'en production : GraphRAG depend des LLMs pour l'extraction, et il ne fait toujours que de la recherche. Il ne raisonne pas.
Synalinks Memory prend une approche completement differente. Pas d'embeddings. Pas d'extraction par LLM. Les graphes de connaissances sont construits a partir de vos donnees semi-structurees en utilisant de la logique pure, instantanement et sans aucun cout. Et quand une question arrive, le systeme raisonne sur le graphe au lieu de simplement recuperer des noeuds pertinents.
Voyons ce que ca donne en pratique.
Comment GraphRAG construit son graphe de connaissances
GraphRAG, tel que popularise par Microsoft Research, fonctionne comme ceci :
- Extraction : Un modele de langage lit vos documents et identifie les entites (personnes, entreprises, concepts) et les relations entre elles
- Construction du graphe : Les triplets extraits (entite-relation-entite) sont assembles en graphe. Des communautes de noeuds lies sont detectees et resumees
- Recherche : Quand une question arrive, le systeme trouve les parties pertinentes du graphe et recupere les resumes ou sous-graphes associes
- Generation : Un modele de langage utilise le contexte du graphe recupere pour generer une reponse
Ca fonctionne mieux que le RAG classique pour les questions qui couvrent plusieurs documents ou qui necessitent de connecter des informations entre differents sujets. La structure de graphe aide a faire remonter des connexions que la similarite vectorielle seule aurait ratees.
Mais il y a des couts reels.
Les problemes de l'extraction par LLM
C'est cher
Chaque document ajoute au systeme doit etre traite par un modele de langage. Pour un corpus important, ca represente des milliers d'appels LLM juste pour construire le graphe initial. Et chaque fois que vos donnees changent, il faut re-extraire. Le cout evolue lineairement avec le volume de donnees, et ca monte vite.
C'est lent
L'extraction n'est pas instantanee. Traiter quelques centaines de documents peut prendre de quelques minutes a plusieurs heures selon le modele et la complexite du texte. Si vos donnees changent frequemment, vous etes toujours en retard.
C'est approximatif
Le LLM decide ce qui constitue une entite et ce qui constitue une relation. Il fait des choix sur ce qui est important et ce qu'il faut ignorer. Ces choix sont probabilistes. Lancez la meme extraction deux fois et vous pouvez obtenir des graphes legerement differents. Des relations importantes peuvent etre completement ratees si le modele ne les reconnait pas comme significatives.
Ca fonctionne surtout sur du texte non structure
GraphRAG a ete concu pour extraire de la structure depuis des documents, PDFs, articles, rapports. Mais une enorme partie des donnees d'entreprise est deja semi-structuree : bases de donnees, tableurs, fichiers CSV. Utiliser un LLM sur une table SQL pour "decouvrir" que les clients ont des commandes, c'est comme utiliser un telescope pour lire un livre pose devant vous. La structure est deja la.
Comment Synalinks construit son graphe de connaissances
Synalinks Memory prend un chemin fondamentalement different :
- Connectez vos donnees : Pointez Synalinks vers vos bases de donnees, tableurs ou fichiers CSV
- Extraction logique : Le systeme lit la structure de vos donnees et construit un graphe de connaissances. Pas d'appels LLM. Pas d'embeddings. De la logique pure
- Graphe instantane : Le graphe de connaissances est disponible immediatement. Pas besoin d'attendre que les pipelines d'extraction se terminent
- Raisonnement : Quand une question arrive, le moteur de raisonnement applique des regles definies au graphe et deduit une reponse. Il ne recupere pas des noeuds pour les passer a un LLM. Il raisonne
Aucun embedding dans le pipeline. Aucun appel LLM pendant l'extraction. Le graphe de connaissances est construit a partir de la structure et du contenu reels de vos donnees, pas a partir de l'interpretation d'un modele.
L'extraction gratuite change tout
Quand l'extraction est gratuite et instantanee, quelque chose d'important se passe : vous pouvez changer d'avis.
Avec GraphRAG, changer votre modele de graphe coute cher. Si vous decidez qu'il vous faut des entites ou des relations differentes, il faut tout re-extraire. Nouveaux appels LLM, nouveaux couts, nouvelle attente. Les equipes ont donc tendance a s'engager sur un schema tot et a s'y tenir, meme quand leurs besoins evoluent.
Avec Synalinks, vous pouvez restructurer votre graphe de connaissances aussi souvent que necessaire. Vous voulez modeliser vos donnees differemment pour repondre a une nouvelle categorie de questions ? Mettez simplement a jour le modele et le graphe se reconstruit instantanement depuis les memes donnees sources. Aucun cout supplementaire, aucune attente.
C'est ce qui rend Synalinks ideal pour les equipes qui cherchent encore quelles questions leurs agents doivent pouvoir traiter. Vous pouvez explorer, iterer et affiner votre modele de connaissances sans vous soucier de bruler des credits LLM a chaque modification.
Recherche vs raisonnement : le vrai ecart
Voici la difference fondamentale qui compte le plus.
GraphRAG recherche. Il trouve les parties pertinentes du graphe et les transmet a un modele de langage pour interpretation. Le LLM doit encore determiner la reponse a partir du contexte recupere. C'est un meilleur contexte que ce que le RAG classique fournit, mais l'etape finale reste de la generation probabiliste.
Synalinks raisonne. Quand vous posez une question, le moteur de raisonnement parcourt le graphe, applique les regles definies et deduit une reponse. Le role du modele de langage se limite a mettre en forme le resultat en langage naturel. Il n'interprete pas, n'infere pas, et ne genere pas le fond de la reponse.
Voici ce que ca donne en pratique :
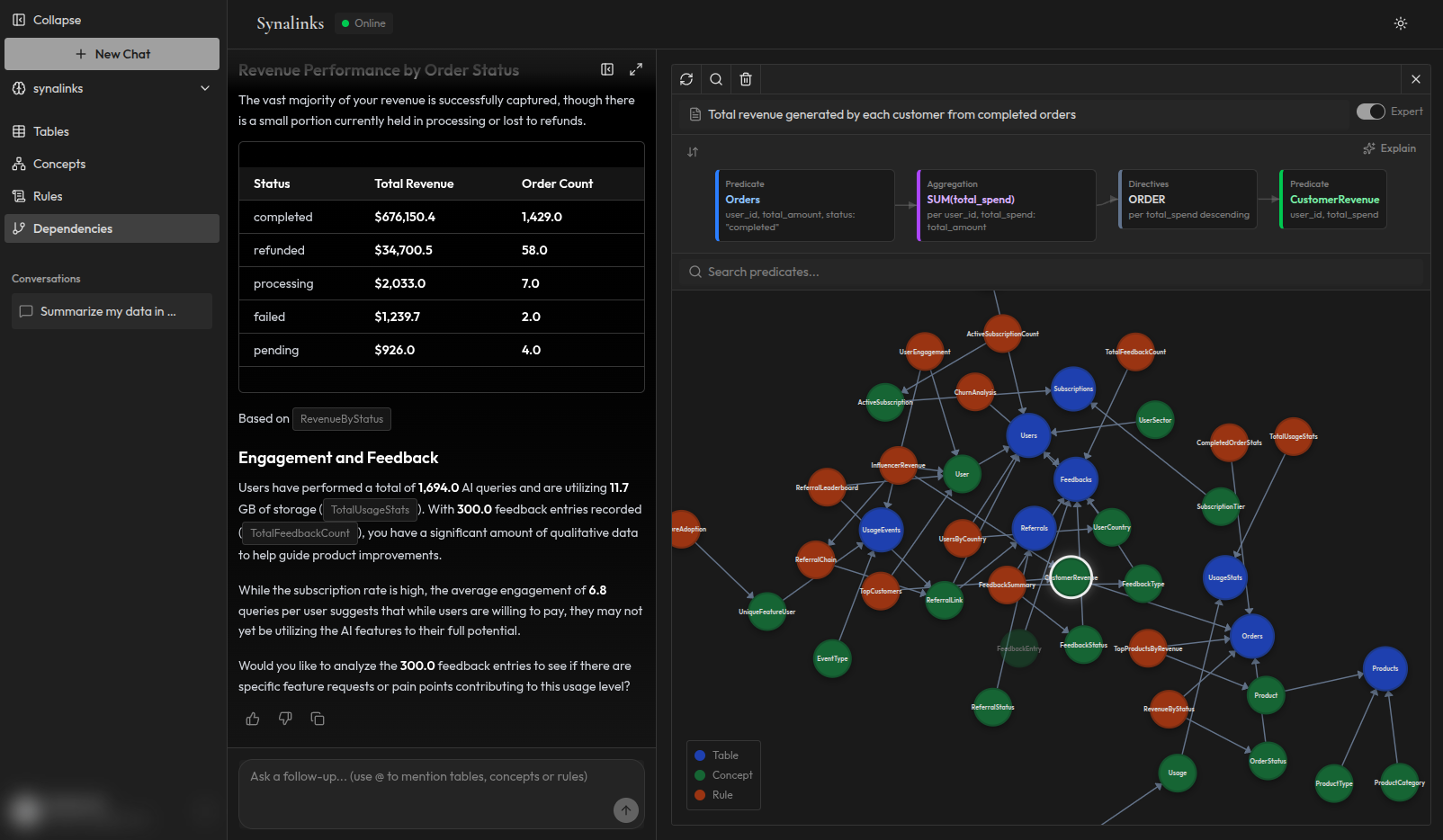
Question : "Quels patients ont le plus grand nombre de rendez-vous ?"
Approche GraphRAG : Le systeme trouve les noeuds du graphe lies a "patients" et "rendez-vous". Il recupere ces sous-graphes et les passe au LLM. Le modele lit le contexte et essaie de connecter les elements. Si certains nombres de rendez-vous manquent dans les noeuds recuperes, le modele pourrait quand meme produire une reponse basee sur ce qu'il a, ou il pourrait rater des patients completement.
Approche Synalinks : Le moteur de raisonnement interroge directement les entités patients via HasAppointmentEdge et PatientNode. Il agrège et classe par volume de visites : Hana Dubois (16 rendez-vous), Hugo Rosso (15), etc. Les regles sont explicites. La reponse est deduite avec des insights de suivi comme "Souhaitez-vous voir quels départements ces patients visitent le plus souvent, ou vérifier s'ils sont associés à des conditions spécifiques ?" Si des donnees manquent, elles sont signalées comme incomplètes, pas ignorées silencieusement.
La difference : une approche espere que le LLM interprete correctement le contexte recupere. L'autre vous donne une reponse prouvable avec une chaine de raisonnement complete.
Quand GraphRAG convient
GraphRAG est un bon choix quand :
- Vos donnees sont principalement du texte non structure (articles de recherche, longs documents, rapports) et vous devez extraire de la structure depuis de la prose
- Vous n'avez pas besoin de reponses deterministes. Une recherche approximative, "suffisamment bonne", est acceptable
- Votre modele de graphe est stable. Vous avez determine quelles entites et relations comptent et vous ne prevoyez pas de les changer souvent
- Vous etendez un pipeline RAG existant et voulez un meilleur raisonnement multi-documents sans changer toute l'architecture
Quand Synalinks convient mieux
Synalinks Memory est le meilleur choix quand :
- Vos donnees sont deja semi-structurees. Tables, bases de donnees, tableurs, fichiers. La structure existe, vous n'avez pas besoin d'un LLM pour la deviner
- Vous avez besoin de vrai raisonnement, pas juste d'une meilleure recherche. Les questions impliquent des regles, des conditions, des comparaisons temporelles et de la logique multi-sauts
- Votre modele de domaine evolue. Vous devez restructurer votre graphe a mesure que votre comprehension du probleme change, sans payer des couts d'extraction a chaque fois
- Le determinisme compte. Meme question, memes donnees, meme reponse. A chaque fois. Avec une trace complete montrant comment la reponse a ete deduite
- Le cout et la vitesse comptent. L'extraction gratuite signifie que vous pouvez faire evoluer votre graphe de connaissances sans vous soucier des factures LLM
Comparaison cote a cote
| GraphRAG | Synalinks Memory | |
|---|---|---|
| Methode d'extraction | LLM (probabiliste) | Logique (deterministe) |
| Utilise des embeddings | Oui | Non |
| Cout d'extraction | Appels LLM par document | Zero |
| Vitesse d'extraction | Minutes a heures | Instantanee |
| Type de donnees ideal | Texte non structure | Semi-structure (tables, BDD, fichiers) |
| Changement de modele | Tout re-extraire (couteux) | Reconstruction instantanee (gratuit) |
| Mecanisme de requete | Recherche + generation LLM | Raisonnement par regles |
| Determinisme des reponses | Non (probabiliste) | Oui (deterministe) |
| Chaines de raisonnement | Non | Oui, trace complete |
| Donnees manquantes | Ignore ou hallucine | Signale explicitement les donnees incompletes |
En resume
GraphRAG est une amelioration reelle par rapport au RAG classique. Si vous travaillez avec de larges collections de documents non structures et que vous devez faire remonter les connexions entre eux, c'est un bon outil.
Mais si vos donnees ont deja de la structure, et c'est le cas de la plupart des donnees d'entreprise, vous payez une taxe inutile en les faisant passer par un LLM juste pour extraire ce qui est deja la. Et vous n'avez toujours pas de vrai raisonnement au moment de la requete.
Synalinks Memory vous donne une extraction de graphe de connaissances instantanee et gratuite a partir de vos donnees reelles, et un moteur de raisonnement qui deduit les reponses au lieu de les rechercher. Quand votre modele de domaine change, vous pouvez reconstruire en quelques secondes. Quand une question arrive, vous obtenez une reponse prouvable, pas une supposition probabiliste.
Les captures d'écran sont fournies à titre illustratif. Le produit final peut différer sur certains aspects. Les données présentées sont synthétiques et utilisées uniquement à des fins de démonstration.