Construire un agent IA sans hallucinations
Équipe Synalinks
Comment construire un agent IA qui n'hallucine jamais sur vos données métier
« Jamais » est un mot fort en IA. Mais quand il s'agit de vos propres données métier, les faits que vous avez vérifiés, les règles que vous avez définies, les relations que vous savez être vraies, l'hallucination n'est pas une fatalité. C'est un choix architectural.
La plupart des agents IA hallucinent parce qu'on leur demande de raisonner sur du texte non structuré. Le modèle de langage reçoit un tas de fragments de documents et doit déterminer ce qui est vrai, ce qui est pertinent, et comment les pièces s'assemblent. C'est là que les erreurs s'infiltrent.
La solution n'est pas de meilleurs prompts ou des réglages de température plus bas. C'est de supprimer entièrement l'opportunité d'hallucination : donner à l'agent des connaissances structurées et vérifiées, et laisser le raisonnement se faire par des règles, pas par prédiction de tokens.
Comprendre pourquoi les hallucinations se produisent
Les hallucinations ne sont pas aléatoires. Elles suivent trois schémas prévisibles :
Schéma 1 : Le modèle comble les lacunes avec de la fiction plausible
Quand le contexte récupéré ne contient pas une réponse complète, le modèle de langage ne dit pas « je ne sais pas ». Il génère quelque chose de plausible. Si votre base de connaissances contient le type de plan du client et sa dernière date de connexion mais pas sa date de renouvellement, le modèle pourrait en déduire une basée sur les patterns appris pendant l'entraînement. Cette inférence pourrait être fausse.
Schéma 2 : Le modèle interprète mal les relations
« L'Entreprise A a acquis l'Entreprise B en 2023 » et « L'Entreprise B est une filiale de l'Entreprise C » peuvent toutes deux apparaître dans les fragments récupérés. Le modèle pourrait conclure que l'Entreprise A a acquis une filiale de l'Entreprise C, alors qu'en réalité l'Entreprise B était indépendante au moment de l'acquisition. Les relations sont temporelles et contextuelles, mais le modèle traite les fragments comme du texte plat et atemporel.
Schéma 3 : Le modèle fusionne des sources contradictoires
Quand plusieurs fragments contiennent des valeurs différentes pour le même point de données (un prix qui a changé, une politique qui a été mise à jour), le modèle doit choisir. Parfois il prend la bonne version. Parfois non. Parfois il génère une valeur qui n'apparaît dans aucune des sources.
Les trois schémas partagent une cause racine : le modèle fait du raisonnement pour lequel il n'est pas conçu, sur des données qui ne sont pas structurées pour le raisonnement.
L'approche par connaissances structurées
Le principe est simple : si vous ne voulez pas que le modèle devine, ne lui donnez rien à deviner.
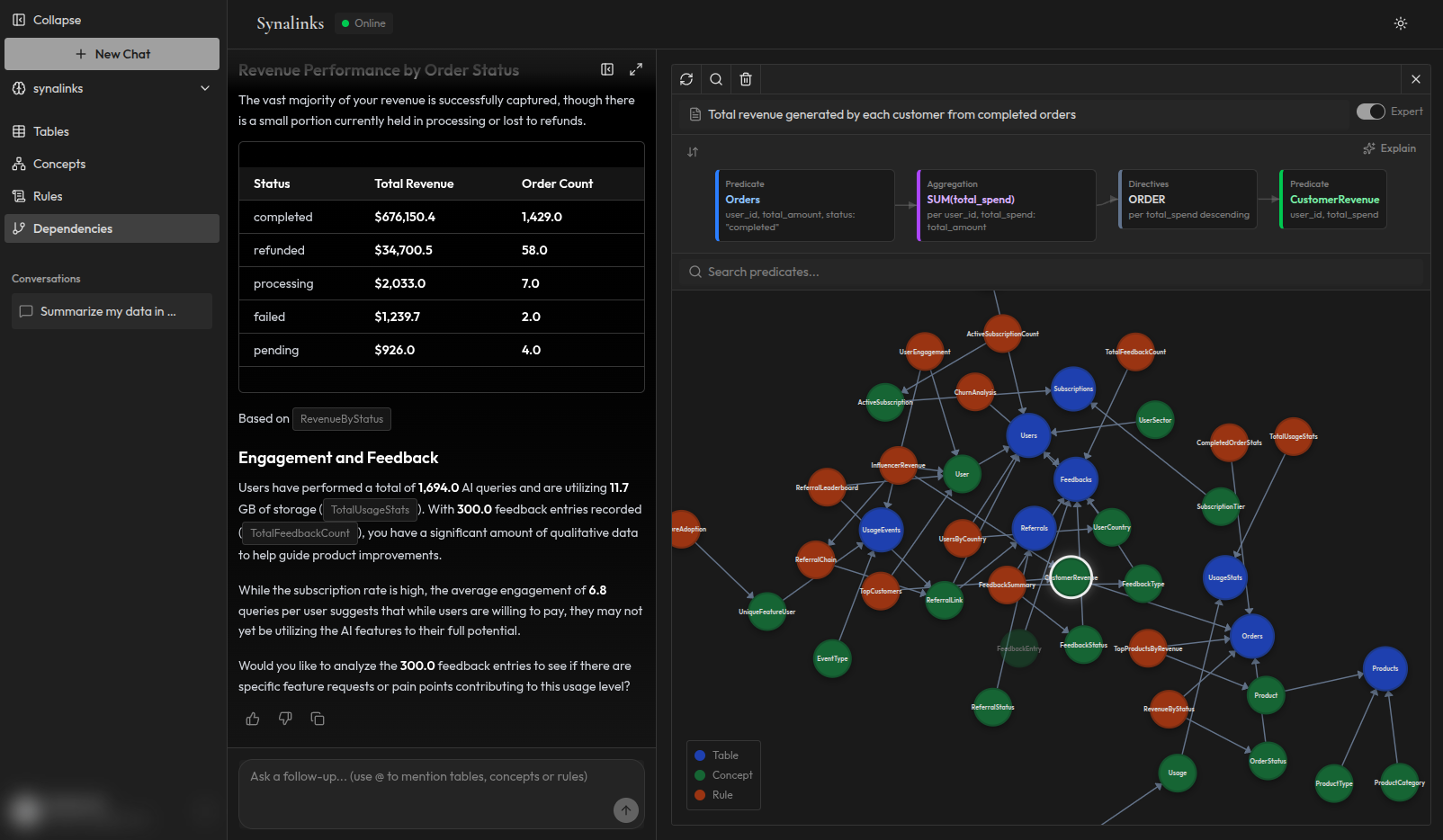
Au lieu de récupérer des fragments de texte en espérant que le modèle les interprète correctement, vous structurez vos connaissances métier en trois couches :
Couche 1 : Faits vérifiés
Chaque point de données dans le système est un fait typé et vérifié. Un patient a un nom, une date de naissance, un historique médical et une liste de rendez-vous. Ce ne sont pas des fragments de texte extraits de documents. Ce sont des enregistrements structurés avec des schémas définis.
Quand un fait n'est pas disponible, le système sait qu'il est manquant. Il n'y a pas de lacune que le modèle pourrait combler avec de la fiction plausible.
Couche 2 : Relations explicites
Les connexions entre entités sont des objets de premier ordre. Le Patient A a un rendez-vous avec le Médecin B. Le Médecin B travaille dans le Département C. Le Patient A a reçu le Traitement D. Ces relations sont typées, directionnelles et vérifiées.
Quand l'agent doit répondre à une question couvrant plusieurs entités, il suit les relations explicites. Il n'a pas à inférer des connexions à partir de la proximité du texte ou de la similarité des embeddings.
Couche 3 : Règles métier
La logique métier est encodée en règles, pas en instructions de prompt. « Patient fréquent » signifie plus de 10 rendez-vous dans l'année. « Charge élevée » signifie un médecin avec plus de 200 rendez-vous par trimestre. « Suivi requis » est déterminé par le type de traitement et les jours depuis la dernière visite.
Ces règles sont appliquées de manière déterministe. Le modèle n'a pas à deviner ce que « patient fréquent » signifie à partir d'indices contextuels dans les documents récupérés. Le système le sait déjà.
Ce qui change dans l'architecture de l'agent
Avec des connaissances structurées en place, l'architecture mémoire de l'agent change fondamentalement :
Avant (RAG) :
- L'utilisateur pose une question
- La question est encodée et des fragments similaires sont récupérés
- Fragments + question vont au modèle de langage
- Le modèle génère une réponse (peut halluciner)
Après (connaissances structurées) :
- L'utilisateur pose une question
- La question est analysée en requête structurée
- Le moteur de raisonnement applique les règles aux faits et relations vérifiés
- Une réponse déduite avec chaîne de raisonnement complète est produite
- Le modèle de langage met en forme la réponse en langage naturel
La différence critique : à l'étape 4 du flux RAG, le modèle raisonne. À l'étape 5 du flux structuré, le modèle ne fait que de la mise en forme. Le raisonnement s'est déjà produit de manière déterministe.
Le modèle peut encore halluciner à l'étape de mise en forme, mais la portée est limitée à la présentation, pas au fond. Il pourrait formuler maladroitement, mais il ne peut pas inventer des faits qui ne sont pas dans le résultat déduit.
Exemple pratique : agent d'analyse médicale
Rendons cela concret. Vous construisez un agent qui répond à des questions sur les données patients d'un système de santé.
La question : « Quels patients ont le plus grand nombre de rendez-vous ? »
Approche RAG : Le système récupère des fragments sur les dossiers patients et les journaux de rendez-vous. Le modèle lit les deux et essaie de compter les rendez-vous par patient. Peut-être que certains rendez-vous manquent dans les fragments récupérés, ou le modèle se trompe dans le comptage parce que les enregistrements sont répartis sur plusieurs documents. Il pourrait quand même donner une réponse. Il ne sait pas ce qu'il ne sait pas.
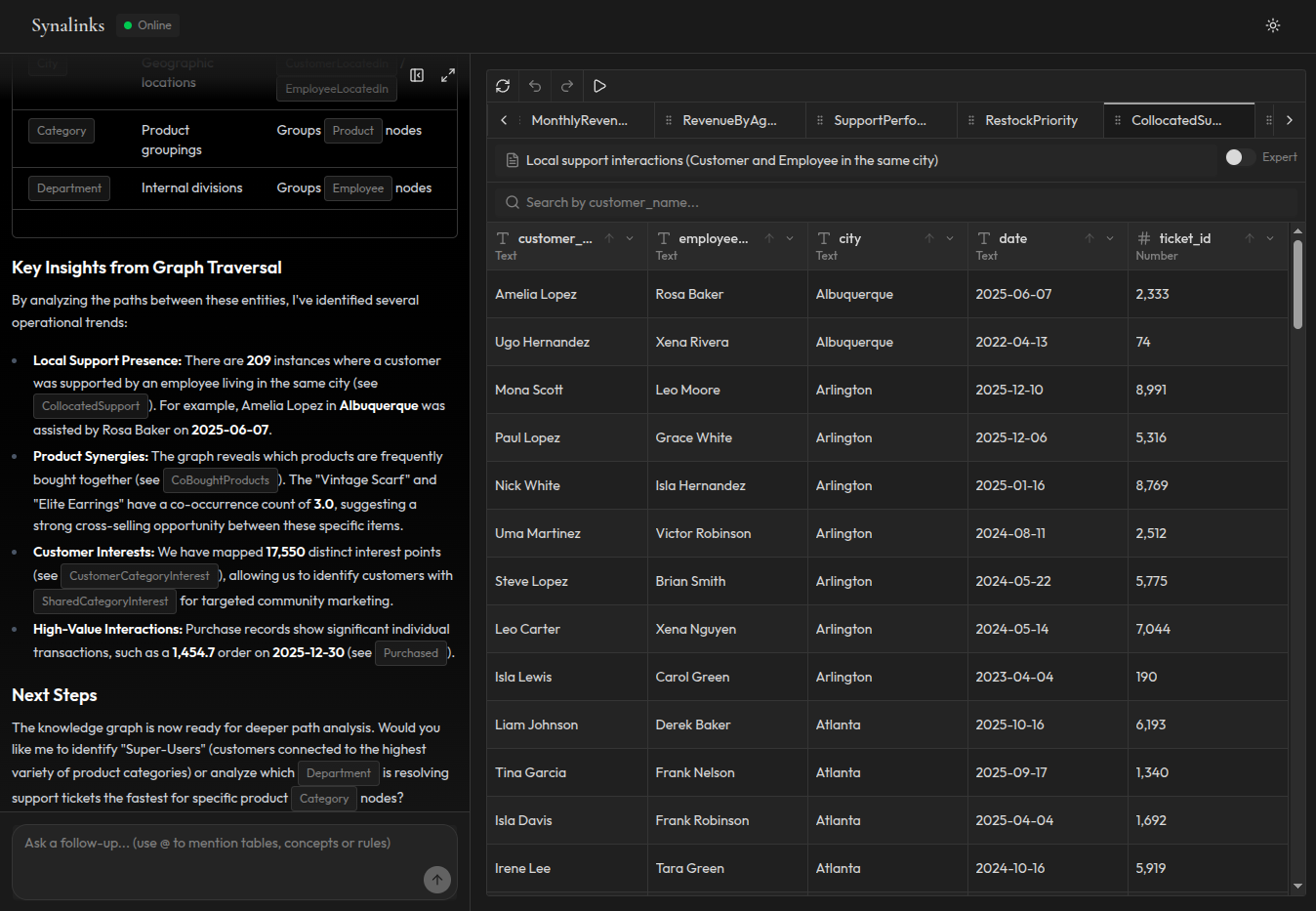
Approche connaissances structurées : Le système a chaque patient comme entité avec des relations de rendez-vous vérifiées via HasAppointmentEdge. Le moteur de raisonnement parcourt le graphe, compte les rendez-vous par patient et les classe : Hana Dubois (16 rendez-vous), Hugo Rosso (15), Clara Martin (14). La chaîne de raisonnement montre exactement quelles relations et quelles données ont produit la conclusion.
Aucune hallucination n'est possible ici. La réponse est déduite, pas générée. Si des données de rendez-vous manquent pour un patient, le système le signale explicitement au lieu de deviner.
L'insight clé : tout peut devenir une règle
Une idée reçue courante est que les questions ouvertes comme « Quelles tendances observez-vous dans les visites de patients ? » ne peuvent pas recevoir de réponse déterministe. Mais si l'analyse de tendances est encodée comme une règle dans vos connaissances structurées, la réponse est déduite, pas générée, et l'hallucination est éliminée de la même manière.
La stratégie est de maximiser la portée des connaissances structurées en encodant autant de logique métier que possible dans des règles : métriques de fréquence de rendez-vous, analyse de charge par département, seuils de résultats de traitement et critères de décision clinique. Plus vous encodez, plus votre agent répond de manière déterministe avec une traçabilité complète.
Commencer avec Synalinks Memory
Synalinks Memory implémente l'approche par connaissances structurées décrite dans cet article. Il donne à vos agents IA une couche de faits vérifiés, de relations explicites et de règles métier pour raisonner de manière déterministe.
- Connectez vos sources de données (bases de données, tableurs, fichiers, API)
- Décrivez votre domaine (entités, relations, règles métier)
- Interrogez de manière déterministe (chaque réponse est accompagnée d'une chaîne de raisonnement complète)
Votre agent arrête de deviner et commence à déduire. Pour vos données métier, l'hallucination devient structurellement impossible.
Les captures d'écran sont fournies à titre illustratif. Le produit final peut différer sur certains aspects. Les données présentées sont synthétiques et utilisées uniquement à des fins de démonstration.